贪心算法是一种基于贪心策略来求解问题的算法,贪心算法的思想是,规定一种清晰且有效的策略,在每一步都选择当前的最优解,以期望达到全局的最优解。在某些情况下,贪心策略可以得到最优解,有些情况下不可以。一个成功的贪心策略是可以达到全局最优解的策略。
贪心算法的特点
- 贪心算法是一种最”自然而且智慧“的算法,就如同大自然的各种事物的发展一样,都是在选择当前最有利的条件来进行。
- 贪心算法用一种局部最功利的标准,总是做出在当前看来是最好的选择。
- 贪心算法的难点在于证明局部最功利的标准可以得到全局最优解。
- 对于贪心算法的学习主要以增加阅历和经验为主。
从一道题目讲起
下面我将从一道经典的贪心算法题,提出不同的贪心策略,并证明这个贪心策略能推导出全局最优解。
题目:找字符串数组字典序最小的排列
给定一个由字符串组成的数组strings,必须把所有的字符串拼接起来,返回所有可能的拼接结果中,字典序最小的结果。
比如,给定 [“df”, “abd”, “d”] ,需要返回:“abdddf”
什么是字典序
字典序是程序中决定两个字符串大小的顺序,比如"abc" 比 “bbc” 小。具体比较方法如下:
-
如果两个字符串长度相等,则从头开始比较,字符比较大的字符串更大,而不用再管后序的字符。
比如:“azzz” 比 “bcde” 小,因为a比b小,虽然后面的z比cde都大,但是仍然是前者小。
-
如果两个字符串长度不相等,则可以想象先将较短的字符串后面补最小的ASCII码,直到与较长的字符串长度相同,然后再比较。
比如:“abcd” 与 “ad"比较,将"ad"看成 “ad00” ,然后比较"abcd"和"ad00”(这里的0是想象中的最小ASCII值,不是真正的0,任何字符都比它大),由于d比b大,所以"ad"比"abcd"大。
-
字典序的本质是将字符串看成一个数字,并比较大小,比如两个一个只由小写字母构成的字符串,可以看做26进制的两个数比较大小。比如 “abc” , “kaj”,由于k高位大,所以 “kaj” 大。同理,如果字符集有65535个字符,则这个字符串可以看做一个65535进制的数字在比较大小。进制不同,但是比较大小的方法是相同的,高位大的就更大。
使用贪心的解题思路
题目的解决思路很简单,我们先将数组按照某种策略排序,保证排序好后的数组中的字符串,一个个拼接起来后,就是所有可能结果中字典序最小的。而排序是基于比较的,比如arr[i] 和 arr[j] 两个位置谁排在前面呢?**这个排序的策略,就是我们的贪心策略。**每次比较时都按照这个策略来决定谁排前面谁排后面(局部最优解),最后所有字符串排好序后,得到的是满足题目要求的(全局最优解)。
所以关键是这个比较策略是什么?
贪心策略1:所有字符串按字典序排好序,然后拼接
比如:
1
2
3
|
["def", "abc", "c"]
按照这个策略排序,得到的结果是:["abc", "c", "def"]
最终的结果就是:"abccdef"
|
用代码实现就是:
1
2
3
4
5
6
7
|
func minConcatenation(arr []string) string {
// 传入的比较器,字典序小的排在前面,字典序大的排后面
sort.Slice(arr, func(i, j int) bool {
return arr[i] < arr[j]
})
return strings.Join(arr, "")
}
|
这种策略能保证整个数组中的字符串,按照字典序从小到大排序,但是能否保证全部拼接后是字典序最小的呢?
答案是:不可以
因为我们很容易举出反例,比如下面这个例子
1
2
3
4
|
["ba","b"]
排完序后是["b", "ba"], 然后结果是 "bba"
但是很明显,正确答案是 "bab" 更小。
|
只要能举出一个反例,就说明这个贪心策略是失败的。
贪心策略2:如果 a·b < b·a 则a放前面,否则b放前面
解释:在排序的过程中,比较 i 和 j 两个位置的字符串 a 和 b 时,将 a和b先拼接起来,再比较。
如果a·b < b·a 则a排前面,否则b排前面。
在上面的例子中,由于"ba·b" < “b·ba”,所以最终"ba"会排在"b"的前面,最终排好序后的数组是:
所以能得到正确的答案"bab"。刚好能满足要求,整体解也符合预期。
用代码实现就是:
1
2
3
4
5
6
7
|
func minConcatenation(arr []string) string {
// 传入的比较器,拼接后再比较 a.b < b.a 则 a 排前面, 否则b排前面
sort.Slice(arr, func(i, j int) bool {
return arr[i]+arr[j] < arr[j]+arr[i]
})
return strings.Join(arr, "")
}
|
那么如何证明这个策略确确实实是正确的贪心策略呢?
证明贪心策略2的正确性
1.证明贪心策略2的排序策略是有传递性的
在上述策略中,假设有
如果能推出 a·c <= c·a,则说明这个策略有传递性。先说结论,能这么推导出,下面是证明:
上文已经提到,字符串比较字典序,本质上是将字符串转换成了数字来比较,比如:
“123” 拼接 “456”,变成 “123456”,实际上是 123 * 1000 + 456。
a·b 本质是个k进制的数。
这个数等于 a * k^len(b) + b(a乘以k的b长度次幂,再加上b)
为了方便数学上的描述,我们假设 k^len(b) 这个用一个函数 m(b)来代替,则有:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
|
上面的字符串拼接,分别可以表示为:
1) a·b = a*m(b) + b
2) b·a = b*m(a) + a
3) b·c = b*m(c) + c
4) c·b = c*m(b) + b
则有:
1) a*m(b) + b <= b*m(a) + a
2) b*m(c) + c <= c*m(b) + b
我们将1)不等式两步共同减去一个b,然后再共同乘以c(由于c是字符串,是非负数,所以乘完后不改变符号方向)
=> a*m(b) <= b*m(a) + a - b
=> a*m(b)*c <= b*m(a)* c + a*c - b*c
我们将2)不等式两边共同减去一个b,然后再乘以a(同理也不改变符号方向)
=> b*m(c) + c - b <= c*m(b)
=> b*m(c)*a + a*c - a*b <= a*m(b)*c
所以有:b*m(c)*a + a*c - a*b <= a*m(b)*c <= b*m(a)* c + a*c - b*c
所以有:b*m(c)*a + a*c - a*b <= b*m(a)*c + a*c - b*c
两边都有a*c,消除掉,得:
a*b*m(c) - a*b <= b*c*m(a) - b*c
将两边的b消除掉,得:
a*m(c) - a <= c*m(a) - c
而这个式子就是:a·c <= c·a
|
由上述推导,我们证明了贪心策略2的排序是具有传递性的。
2.证明数组中排完序后,整体的字典序最小
假设排完序之后,a是任意一个在前的字符串,b是任意一个在后的字符串,如下:
1
|
[......a.......b......]
|
现在要证明,如果将a和b交换位置,整体字典序一定是增大了,证明如下:
1
2
3
4
5
6
7
8
9
10
11
12
13
|
我们假设a和b之间只隔着两个字符串m1和m2,如下所示:
[......a,m1,m2,b......]
由于这是排好序的,所以 a·m1 肯定 <= m1·a
[......a,m1,m2,b......] <= [......m1,a,m2,b......]
同理,a在m2前面,a·m2 <= m2·a,所以如果继续将m2和a交换,有
[......m1,a,m2,b......] <= [......m1,m2,a,b......]
同理有
[......m1,m2,a,b......] <= [......m1,m2,b,a......]
[......m1,m2,b,a......] <= [......m1,b,m2,a......]
[......m1,b,m2,a......] <= [......b,m1,m2,a......]
由于上面已经证明了这种排序策略具有传递性,所以最终有:
[......a,m1,m2,b......] <= [......b,m1,m2,a......]
说明:任意交换最终数组中的任意两个字符串,都会使得最终的字典序增大。
|
事实上,上述结论虽然只举例了中间有两个字符串,但不难看出无论a和b之间有多少个字符串,只要交换任意的a和b,都会导致最终的字典序增大。所以拍完序后,整体的字典序一定是最小的,证明完毕。
贪心方法论
我们发现,上面这个严格的证明,只能针对这一道题的这一个策略。一旦题目变了,策略变了,这个证明就无用了,实际上贪心策略的严格数学证明是很难的。
而我们都是先提出了贪心策略,再去证明的。
所以我们只需要证明这个贪心策略是否能得到全局最优解(是否是对的)。我们可以使用以下方法:
-
如果一个策略能很快的举出反例,则说明这个贪心策略是失败的,直接跳过
-
如果举不出反例,除了上述的严格数学推导外,我们其实可以简单的直接做实验来验证,我们可以使用对数器来验证。
对数器的步骤如下:
- 先用一个暴力的复杂度高但是容易实现的方式来实现(不一定用了贪心)
- 用我们想到的贪心策略来实现
- 用代码生成随机数据样本
- 写一个测试函数,测试随机数据样本,测试10万次(或者更多更少,视情况而定),如果每次暴力方法和贪心方法得到的结果一致,则证明了这个贪心是正确的。
- 如果测试发现不一致,说明这个贪心策略是错的,我们重新想一个贪心策略,重复4步骤,直到正确为止。
注意:在测试过程中,可以灵活调整样本大小、测试的次数等,已达到验证的目的。
以上才是解决贪心算法的方法。我们不需要去证明,而是直接实验验证策略的正确性。
对数器解上面的题
既然提到了对数器的方式验证,我们可以使用对数器重新解上面的题。首先我们需要实现一个纯暴力的方式,暴力方式的思路如下:
- 我们暴力获取这个字符串数组所有可能的排列组合后的字符串
- 从所有排列组合拼接得到的字符串中找到字典序最小的
暴力方法代码如下:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
|
// 方法一:暴力方法,获取所有可能的排列组合,并得到字典序最小的
func minConcatenation1(arr []string) string {
if len(arr) == 0 {
return ""
}
// 得到所有可能的排列组合拼接后的结果
ans := process1(arr)
// 将这些结果按照字典序从小到大排序
sort.Slice(ans, func(i,j int) bool {
return ans[i] < ans[j]
})
// 第1个就是要返回的值
return ans[0]
}
// 传入一个字符串数组,返回所有排列组合后拼接的字符串结果
// 比如传入 ["ab", "cd"]
// 会返回 ["abcd", "cdab"]
func process1(arr []string) []string {
ans := make([]string, 0)
if len(arr) == 0 {
ans = append(ans, "")
return ans
}
// 以i位置的字符串开头,然后将删除i位置的字符串后,剩下的字符串列表继续排列组合,并在头部拼接上i位置的字符串
for i := 0; i < len(arr); i++ {
first := arr[i]
removedList := removeIndexString(arr, i)
next := process1(removedList)
for _, cur := range next {
ans = append(ans, first + cur)
}
}
return ans
}
// 删除i位置的字符串,返回新的数组
func removeIndexString(arr []string, index int) []string {
N := len(arr)
if N == 0 {
return nil
}
ans := make([]string, N-1)
ansIndex := 0
for i:=0; i < N; i ++ {
if i != index {
ans[ansIndex] = arr[i]
}
}
return ans
}
|
我们的贪心方法如下:
1
2
3
4
5
6
|
func minConcatenation2(arr []string) string {
sort.Slice(arr, func(i, j int) bool {
return arr[i]+arr[j] < arr[j]+arr[i]
})
return strings.Join(arr, "")
}
|
对数器测试代码如下
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
|
package class_14
import (
"math/rand"
"testing"
"time"
)
func TestMinConcatenation(t *testing.T) {
testTimes := 100000 // 测试次数
maxStrLength := 5 // 样本中最大字符串长度
maxArrayLength := 6 // 样本中数组最大大小
t.Log("测试开始...")
for i := 0; i < testTimes; i++ {
arr := generateRandomStrArr(maxStrLength, maxArrayLength)
arr1 := copyStringArray(arr)
arr2 := copyStringArray(arr)
ans1 := minConcatenation1(arr)
ans2 := minConcatenation2(arr1)
if ans1 != ans2 {
t.Errorf("测试失败\n 数组为:%v\n 暴力方法结果:%s\n 贪心方法结果: %s", arr2, ans1, ans2)
return
}
}
t.Log("测试成功")
}
const letterBytes = "abcdefghijklmnopqrstuvwxyz"
func generateRandomStrArr(maxStrLength, maxLength int) []string {
myRand := rand.New(rand.NewSource(time.Now().UnixNano()))
ans := make([]string, 0)
n := myRand.Intn(maxLength + 1)
for i := 0; i < n; i++ {
ans = append(ans, generateRandomString(maxStrLength))
}
return ans
}
func generateRandomString(maxLength int) string {
myRand := rand.New(rand.NewSource(time.Now().UnixNano()))
length := myRand.Intn(maxLength+1) + 1
b := make([]byte, length)
for i := range b {
b[i] = letterBytes[myRand.Intn(len(letterBytes))]
}
return string(b)
}
func copyStringArray(arr []string) []string {
// 创建一个新的字符串数组,长度与输入数组相同
copiedArray := make([]string, len(arr))
// 使用循环将每个元素复制到新数组中
for i, value := range arr {
copiedArray[i] = value
}
return copiedArray
}
|
跑测试的结果如下:
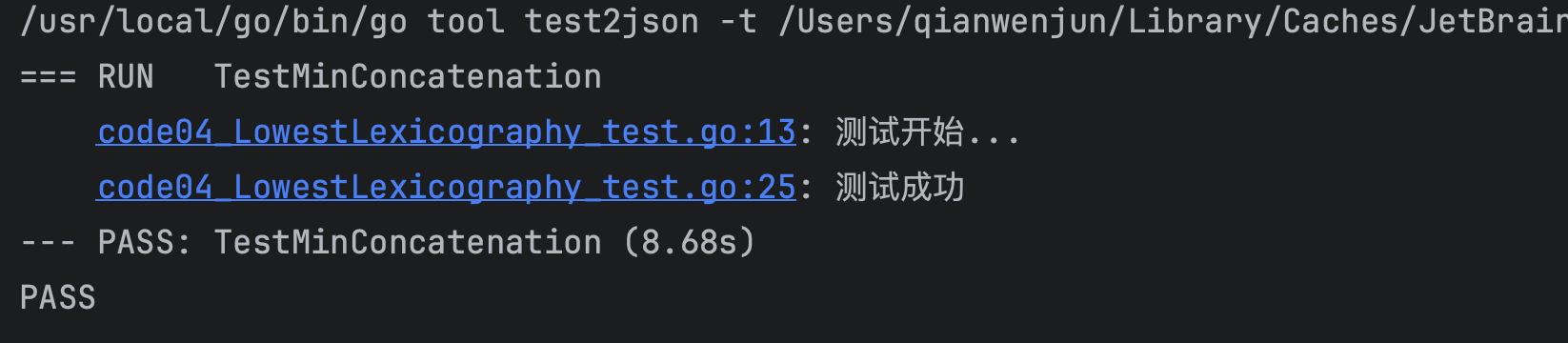
贪心算法的解题套路
-
实现一个不依靠贪心策略的解法X,可以用最暴力的尝试
-
脑补出贪心策略A、贪心策略B、贪心策略C…
-
用解法X和对数器,用实验的方式(对数器)得知哪个贪心策略正确
-
不要去纠结贪心策略的证明