二叉树
二叉树是经典的数据结构,拥有一个Value和左右两个子树。
二叉树的遍历
二叉树的遍历一般分为先序遍历,中序遍历和后序遍历3种。
- 先序遍历:先打印根节点,再打印左子树,最后打印右子树。
- 中序遍历:先打印左子树,再打印根节点,最后打印右子树。
- 后序遍历:先打印左子树,再打印右子树,最后打印根节点。
这3种遍历其实都是人为规定的,总共的遍历方式其实有6种,比如先打印右子树,再打印左子树,最后打印根节点,这种算什么遍历呢?
另外,二叉树的遍历还有按层遍历,即按照每层依次从左往右打印,比如
1
2
3
4
5
6
|
1
/ \
2 3
/ \ / \
4 5 6 7
遍历就是:1 2 3 4 5 6 7
|
递归方式遍历二叉树
1.先序遍历
1
2
3
4
5
6
7
8
9
10
11
12
|
// Pre 先序遍历
func (r *RecursiveTraversalBT) Pre(root *Node) {
if root == nil {
return
}
// 先打印根节点
fmt.Printf("%d ", root.Value)
// 再打印左子树
r.Pre(root.Left)
// 再打印右子树
r.Pre(root.Right)
}
|
2.中序遍历
1
2
3
4
5
6
7
8
9
10
11
12
|
// In 中序遍历
func (r *RecursiveTraversalBT) In(root *Node) {
if root == nil {
return
}
// 先打印左子树
r.In(root.Left)
// 再打印自己
fmt.Printf("%d ", root.Value)
// 最后打印右子树
r.In(root.Right)
}
|
3.后序遍历
1
2
3
4
5
6
7
8
9
10
11
12
|
// Pos 后序遍历
func (r *RecursiveTraversalBT) Pos(root *Node) {
if root == nil {
return
}
// 先打印左子树
r.Pos(root.Left)
// 再打印右子树
r.Pos(root.Right)
// 最后打印自己
fmt.Printf("%d ", root.Value)
}
|
递归序
递归序指的是,在遍历过程中,每个节点都会到达3次,第1次是遍历到当前节点,第2次是遍历完左子树,回到当前节点,第3次是遍历完又子树,回到当前节点。
1
2
3
4
5
6
7
8
9
10
11
12
|
func f(root *Node) {
if root == nil {
return
}
fmt.Println("第一次到达")
// 遍历左子树
f(root.Left)
fmt.Println("第二次到达")
// 遍历右子树
f(root.Right)
fmt.Println("第三次到达")
}
|
先序遍历的本质就是第1次到达当前节点时打印。
中序遍历的本质就是第2次到达当前节点时打印。
后序遍历的本质就是第3次到达当前节点时打印。
使用非递归的方式遍历二叉树
1.先序遍历
准备一个栈,然后流程如下
- 将根节点入栈,栈不空就一直遍历
- 弹出栈顶元素并给cur,弹出就打印。
- 如果有右子树,右子树入栈,如果有左子树,左子树入栈(先入右再入左)
- 不断重复2和3步骤,直到栈弹空。
理解:对于每一颗子树来说,都是先根节点入栈,再弹出,然后右子树入栈再左子树入栈。所以弹出时是
先弹出根,再左再右,每颗子树都是如此,所以整体的顺序就是先序遍历的顺序。
代码如下:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
|
// Pre 先序遍历
func (r *UnRecursiveTraversalBT) Pre(root *Node) {
if root == nil {
return
}
// 创建一个栈,并先把根节点压入
stack := class_03.NewMyStack[*Node]()
stack.Push(root)
for !stack.IsEmpty() {
cur := stack.Pop()
// 出栈就打印
fmt.Printf("%d ", cur.Value)
// 有右子树,就入栈
if cur.Right != nil {
stack.Push(cur.Right)
}
// 有左子树,就入栈
if cur.Left != nil {
stack.Push(cur.Left)
}
}
fmt.Println()
}
|
2.后续遍历
从先序遍历的流程,我们用栈实现了先头再左再右的先序遍历顺序打印,用的方式是头入栈之后出栈,然后将头的右左子树分别入栈。
那么我们也可以实现先头再右再左的打印,方式是弹出头后,先入栈左子树,再入栈右子树。
进一步,上面的流程是一出栈就打印,如果我们在上面的基础上改动,一出栈就不打印,而是压入另一个栈。整个事情做完之后,再将另一个栈依次打印。
那么,最后打印的顺序是 头右左 的逆序,也就是 左右头,也就实现了后序遍历。
代码如下:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
|
// Pos1 后序遍历
func (r *UnRecursiveTraversalBT) Pos1(root *Node) {
if root == nil {
return
}
s1 := class_03.NewMyStack[*Node]()
s2 := class_03.NewMyStack[*Node]()
s1.Push(root)
for !s1.IsEmpty() {
head := s1.Pop()
// 只要出栈,不打印,而是压入另一个栈
s2.Push(head)
// 弹出后依次压入左和右,实现整体 头 右 左 的顺序弹出
if head.Left != nil {
s1.Push(head.Left)
}
if head.Right != nil {
s1.Push(head.Right)
}
}
// 所有事情做完,依次将s2弹出
for !s2.IsEmpty() {
fmt.Printf("%d ", s2.Pop().Value)
}
}
|
4. 怎么只使用一个栈,实现后序遍历
这个流程很难,基本上面试官也没有多少会的,左神在课上没讲,只给了代码,可以掌握也可以不掌握。代码如下:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
|
public static void pos2(Node h) {
System.out.print("pos-order: ");
if (h != null) {
Stack<Node> stack = new Stack<Node>();
stack.push(h);
Node c = null;
while (!stack.isEmpty()) {
c = stack.peek();
if (c.left != null && h != c.left && h != c.right) {
stack.push(c.left);
} else if (c.right != null && h != c.right) {
stack.push(c.right);
} else {
System.out.print(stack.pop().value + " ");
h = c;
}
}
}
System.out.println();
}
|
5.中序遍历
中序遍历是先左子树,然后头节点,最后右子树。对于不管多高的二叉树,最先遍历到的,一定是左边界的最后一个节点,然后是头节点和右子树。
所以中序遍历的本质是,将整颗树按照左边界做了一个拆分。
中序遍历的流程如下:
准备一个栈和一个cur变量,初始时cur指向根节点,循环条件是栈不为空或者cur不为空(栈为空且cur为空,就退出)
- 如果cur不为空,cur入栈,cur跳到cur的左子树。
- 如果cur为空,则栈弹出一个节点给cur接收,同时打印,同时cur指向cur的右子树。
- 重复上述过程,直到cur为空且栈也弹空了,退出。
具体实例:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
|
我们以这颗树为例:
1
/ \
2 3
/ \ / \
4 5 6 7
1. 初始cur不断往左边界走,直到走到4,一直入栈,stack = 1 2 4 栈顶是4,此时cur走到4的左孩子,是空
2. 弹出4打印,栈是 1 2,cur指向4的右孩子,cur又是空
3. 弹出2打印,栈是 1,cur指向2的右孩子为5,不为空,5入栈,栈是 1 5,cur来到5的左孩子,是空
4. 弹出5打印,栈是 1,cur指向5的右孩子为空
5. 弹出1打印,栈是空,cur指向1的右孩子,是3
6. 3入栈,栈是3,cur指向3的左孩子6
7. 6入栈,栈是3 6,cur指向6的左孩子,为空
8. 弹出6打印,栈是3,cur指向6的右孩子为空
9. 弹出3打印,栈为空,cur指向3的右孩子7
10.7入栈,栈是7,cur指向7的左孩子,是空
11.弹出7打印,cur指向7的右孩子,是空,此时栈是空,cur也是空,循环退出。
至此,依次打印了 4 2 5 1 6 3 7
|
代码如下:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
|
// In 中序遍历
func (r *UnRecursiveTraversalBT) In(root *Node) {
if root == nil {
return
}
// 创建一个栈,如果当前节点有左孩子,就压入,并不断往左边界靠
stack := class_03.NewMyStack[*Node]()
cur := root
for !stack.IsEmpty() || cur != nil {
if cur != nil {
stack.Push(cur)
cur = cur.Left
} else {
cur = stack.Pop()
fmt.Printf("%d ", cur.Value)
cur = cur.Right
}
}
fmt.Println()
}
|
6.实现按层遍历
如果将二叉树理解为图,则按层遍历是宽度优先搜索,用队列实现。
准备一个队列,并先将根节点放队列里。
- 从队列里弹出一个节点,打印,并给cur
- cur如果有左孩子,左孩子入队列,如果有右孩子,右孩子入队列
- 循环1 2步骤,直到队列为空。
举例:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
|
我们以这颗树为例:
1
/ \
2 3
/ \ / \
4 5 6 7
1. 1入队列
2. 1弹出,打印,1给cur,cur的左右子树入队列[2,3]
3. 2弹出,打印,2给cur,cur的左右子树入队列[3,4,5]
4. 3弹出,打印,3个cur,cur的左右子树入队列[4,5,6,7]
5. 4弹出,打印,无左右子树,不入队列
6. 5弹出,打印,无左右子树,不入队列
7. 6弹出,打印,无左右子树,不入队列
8. 7弹出,打印,入左右子树,不入队列
综上,整体打印顺序是 1 2 3 4 5 6 7 按照层遍历。
|
总结:这个流程是按照层遍历的,但是我们不知道遍历时每一层的开始和结束。有些算法题需要直到,比如求最大的层宽度。
二叉树的序列化和反序列化
给一个内存中的二叉树,能将这个二叉树用某种规则转换成一个唯一的字符串,并且可以根据这个字符串反转成当前唯一的二叉树。这就是序列化和反序列化。
常规的方式是按先序遍历方式序列化和按层遍历方式序列化。
比如:先序遍历中,遇到nil不忽略,用#表示,遇到正常节点,拼接值,并所有都用,隔开。
1
2
3
4
5
6
7
8
9
10
11
|
1
/ \
2 3
/ \ / \
4 5 6 7
/\ / \ / \ / \
nil nil nil nil nil nil nil nil
先序方式序列化就是: "1,2,4,#,#,5,#,#,3,6,#,#,7,#,#"
反序列化时,也是按照先序的方式重新建树
|
二叉树可以通过先序、后序或者按层遍历的方式序列化和反序列化。
但是,二叉树无法通过中序遍历的方式实现序列化和反序列化
因为不同的两棵树,可能得到同样的中序序列,即便补了空位置也可能一样。
比如如下两棵树
1
2
3
4
5
6
7
8
|
__2
/
1
和
1__
\
2
|
补足空位置的中序遍历结果都是{ null, 1, null, 2, null} (#,1,#,2,#)
关于空树
序列化成字符串,如果序列化后的值是"#",不管是先序、后序还是按层遍历的方式,都表示只有一个节点,且为空(即空树)。而空字符串,也能表示空树。
为了避免歧义,我们这里规定序列化空树,一定序列化成"#"。反序列化时,如果出现了空字符串和"#",则都反序列化为空树。
代码实现
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94
95
96
97
98
99
100
101
102
103
104
105
106
107
108
109
110
111
112
113
114
115
116
117
118
119
120
121
122
123
124
125
126
127
128
129
130
131
132
133
134
135
136
137
138
139
140
141
142
143
144
145
146
147
148
149
150
151
152
153
154
155
156
157
158
159
160
161
162
163
164
165
166
167
168
169
170
171
172
173
174
175
176
177
178
179
180
181
182
183
184
185
186
187
188
189
190
191
192
193
194
195
196
197
198
199
200
201
202
203
204
205
206
207
208
209
210
211
212
213
214
215
216
217
218
219
220
221
222
223
224
225
226
227
228
229
230
231
232
233
234
235
236
237
238
239
240
241
242
243
244
245
246
247
248
249
250
251
252
253
254
255
256
257
258
259
260
261
262
|
// 序列化和反序列化二叉树
// 给定一个二叉树的头节点,返回序列化后的字符串
// 规则:节点值之间用逗号隔开,空节点用#表示
// SerializeAndReconstructBT 实现二叉树的序列化和反序列化
type SerializeAndReconstructBT struct{}
// PreSerialize 先序方式序列化成字符串
func (s *SerializeAndReconstructBT) PreSerialize(head *TreeNode) string {
queue := class_03.NewMyQueue[string]()
// 序列化
s.preSerialize(head, queue)
// 将队列转换成字符串
return s.queueToStr(queue)
}
// 递归方式实现先序序列化
func (s *SerializeAndReconstructBT) preSerialize(head *TreeNode, queue *class_03.MyQueue[string]) {
if head == nil {
queue.Push("#")
} else {
// 先入队
queue.Push(strconv.Itoa(head.Val))
// 再递归左子树和右子树
s.preSerialize(head.Left, queue)
s.preSerialize(head.Right, queue)
}
}
// InSerialize 中序方式序列化成字符串
func (s *SerializeAndReconstructBT) InSerialize(head *TreeNode) string {
queue := class_03.NewMyQueue[string]()
// 序列化
s.inSerialize(head, queue)
// 将队列转换成字符串
return s.queueToStr(queue)
}
// 递归方式实现中序序列化
func (s *SerializeAndReconstructBT) inSerialize(head *TreeNode, queue *class_03.MyQueue[string]) {
if head == nil {
queue.Push("#")
} else {
// 先执行左子树
s.inSerialize(head.Left, queue)
// 再入队
queue.Push(strconv.Itoa(head.Val))
// 再执行右子树
s.inSerialize(head.Right, queue)
}
}
// PosSerialize 后序方式序列化成字符串
func (s *SerializeAndReconstructBT) PosSerialize(head *TreeNode) string {
queue := class_03.NewMyQueue[string]()
// 序列化
s.posSerialize(head, queue)
// 将队列转换成字符串
return s.queueToStr(queue)
}
// 递归方式实现后序序列化
func (s *SerializeAndReconstructBT) posSerialize(head *TreeNode, queue *class_03.MyQueue[string]) {
if head == nil {
queue.Push("#")
} else {
// 先执行左子树
s.posSerialize(head.Left, queue)
// 再执行右子树
s.posSerialize(head.Right, queue)
// 再入队
queue.Push(strconv.Itoa(head.Val))
}
}
func (s *SerializeAndReconstructBT) queueToStr(queue *class_03.MyQueue[string]) string {
if queue == nil || queue.IsEmpty() {
return ""
}
var ans string
isFirst := true
for !queue.IsEmpty() {
if isFirst {
ans += queue.Poll()
isFirst = false
} else {
ans += "," + queue.Poll()
}
}
return ans
}
// LevelSerialize 按层遍历序列化
func (s *SerializeAndReconstructBT) LevelSerialize(head *TreeNode) string {
queue := class_03.NewMyQueue[string]()
// 序列化
// 准备一个Node队列,用来实现按层遍历的
nodeQueue := NewTreeNodeQueue()
// 头节点先入队列
nodeQueue.Push(head)
for !nodeQueue.IsEmpty() {
// 先出队列一个
head = nodeQueue.Poll()
// 出队列就加入序列化,可能是空,要判断,空就序列化成#
if head == nil {
queue.Push("#")
} else {
queue.Push(strconv.Itoa(head.Val))
// 左右子树入队列,不判断空,因为空也要序列化
nodeQueue.Push(head.Left)
nodeQueue.Push(head.Right)
}
}
// 将队列转换成字符串
return s.queueToStr(queue)
}
// 反序列化
// BuildByPreSerialize 通过先序遍历序列化后的字符串反序列化成树
func (s *SerializeAndReconstructBT) BuildByPreSerialize(preSer string) *TreeNode {
// 空树
if preSer == "" || preSer == "#" {
return nil
}
// 还原成序列化队列
preQueue := s.getQueue(preSer)
// 根据队列来构建目标树
ans := s.buildByPreQueue(preQueue)
return ans
}
func (s *SerializeAndReconstructBT) buildByPreQueue(queue *class_03.MyQueue[string]) *TreeNode {
// 从队列中取出一个,作为头节点
head := s.buildNodeByQueue(queue)
// 递归
if head != nil {
head.Left = s.buildByPreQueue(queue)
head.Right = s.buildByPreQueue(queue)
}
return head
}
// BuildByPosSerialize 通过后序遍历序列化后的字符串反序列化成树
// 1
// / \
// 2 3
// /
// 4
// #,#,2,#,#,4,#,3,1
func (s *SerializeAndReconstructBT) BuildByPosSerialize(posSer string) *TreeNode {
// 空树
if posSer == "" || posSer == "#" {
return nil
}
// 后序遍历队列顺序:左 右 头, 先是左子树,再是右子树,最后是头节点
// 而先序遍历我们已经实现了,先序遍历为:头,左,右。
// 在改后序遍历非递归方法的代码时,我们是先将先序遍历的 头,左,右 改成 头,右,左 (这个改动很简单,交换两行代码顺序就能做到,本质是一样的)
// 然后再用一个栈来逆序,改成了 左,右,头的顺序,也就是实现了后序遍历(每次要打印时,不打印,而是入栈,最后弹出)
// 这里也是一样,如果将posSer的值按顺序压入一个栈中,则变成了 头,右,左的顺序,然后我们再按照先序遍历的方式处理
// 还原成序列化栈
posStack := s.getStack(posSer)
// 根据队列来构建目标树
ans := s.buildByPosStack(posStack)
return ans
}
func (s *SerializeAndReconstructBT) buildByPosStack(posStack *class_03.MyStack[string]) *TreeNode {
// 当前栈是 头 右 左的顺序,先弹出的是头,再弹出的是右子树,再弹出的是左子树
// 1. 弹出头的值
strValue := posStack.Pop()
if strValue == "#" {
return nil
}
// 先构建头节点
headValue, _ := strconv.Atoi(strValue)
head := &TreeNode{Val: headValue}
// 递归,构建左右子节点,注意栈中的顺序是 头 右 左,所以构建时,也要遵循先右后左的顺序
if head != nil {
head.Right = s.buildByPosStack(posStack)
head.Left = s.buildByPosStack(posStack)
}
return head
}
// BuildByLevelSerialize 按层遍历的方式反序列化
// 1
// / \
// 2 3
// /
// 4
// 1,2,3,#,#,4,#,#,#
func (s *SerializeAndReconstructBT) BuildByLevelSerialize(preSer string) *TreeNode {
// 空树
if preSer == "" || preSer == "#" {
return nil
}
// 还原成序列化队列
preQueue := s.getQueue(preSer)
// 根据队列来构建目标树
ans := s.buildByLevelQueue(preQueue)
return ans
}
func (s *SerializeAndReconstructBT) buildByLevelQueue(queue *class_03.MyQueue[string]) *TreeNode {
head := s.buildNodeByQueue(queue)
// 构建一个Node队列
nodeQueue := NewTreeNodeQueue()
// 头节点入队列
nodeQueue.Push(head)
for !nodeQueue.IsEmpty() {
// 头节点出队列
node := nodeQueue.Poll()
// 构建当前head的左子树 queue中的下两个一定是当前节点的左右子树
left := s.buildNodeByQueue(queue)
right := s.buildNodeByQueue(queue)
if node != nil {
node.Left = left
node.Right = right
if left != nil {
nodeQueue.Push(left)
}
if right != nil {
nodeQueue.Push(right)
}
}
}
return head
}
func (s *SerializeAndReconstructBT) getQueue(serialized string) *class_03.MyQueue[string] {
queue := class_03.NewMyQueue[string]()
for _, str := range strings.Split(serialized, ",") {
queue.Push(str)
}
return queue
}
func (s *SerializeAndReconstructBT) getStack(serialized string) *class_03.MyStack[string] {
stack := class_03.NewMyStack[string]()
for _, str := range strings.Split(serialized, ",") {
stack.Push(str)
}
return stack
}
func (s *SerializeAndReconstructBT) buildNodeByQueue(queue *class_03.MyQueue[string]) *TreeNode {
if queue.IsEmpty() {
return nil
}
v := queue.Poll()
if v == "#" {
return nil
} else {
nodeValue, _ := strconv.Atoi(v)
return &TreeNode{Val: nodeValue}
}
}
|
代码详见:
code04_serialize_and_reconstruct_tree.go
算法面试题:将N叉树转码为二叉树
Encode N-ary Tree to Binary Tree
leetCode原题链接:https://leetcode.cn/problems/encode-n-ary-tree-to-binary-tree/
设计一个算法,可以将 N 叉树编码为二叉树,并能将该二叉树解码为原 N 叉树。一个 N 叉树是指每个节点都有不超过 N 个孩子节点的有根树。类似地,一个二叉树是指每个节点都有不超过 2 个孩子节点的有根树。你的编码 / 解码的算法的实现没有限制,你只需要保证一个 N 叉树可以编码为二叉树且该二叉树可以解码回原始 N 叉树即可。
这个二叉树可以认为是这颗多叉树的序列化结果,能够重新转换回原来的多叉树。
例如,你可以将下面的 3-叉 树以该种方式编码:
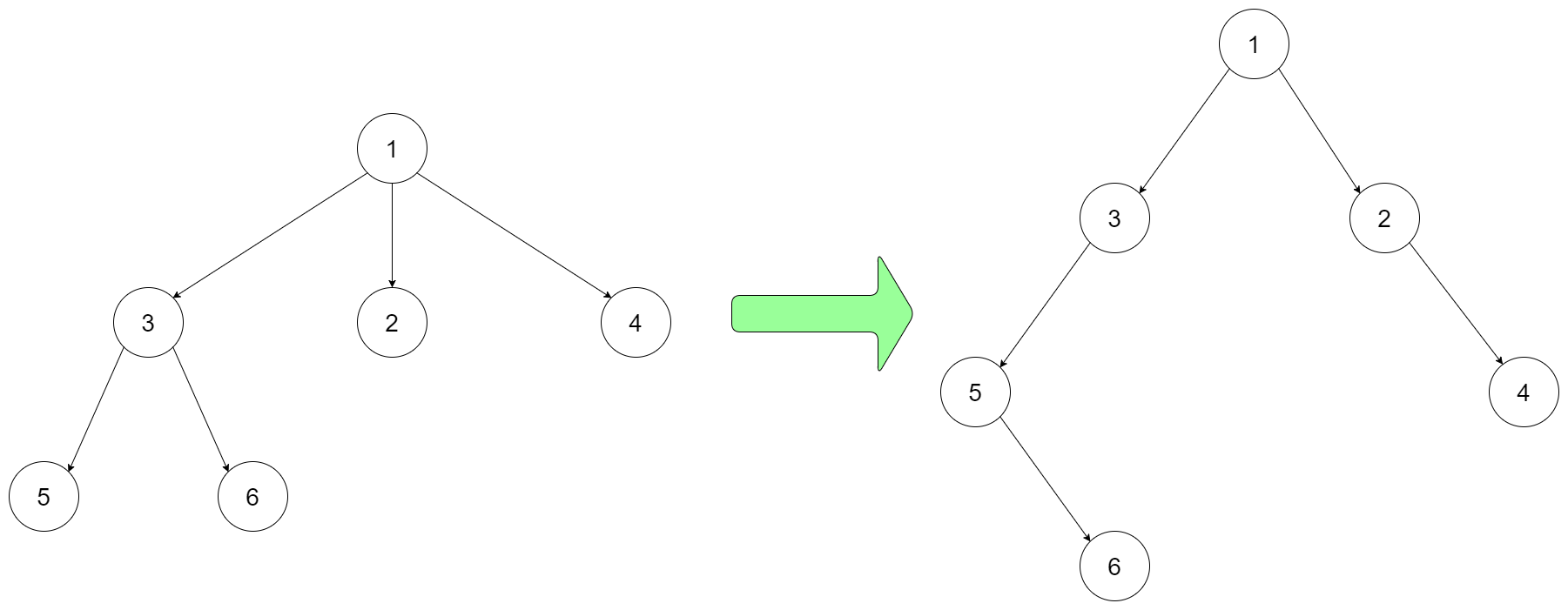
注意,上面的方法仅仅是一个例子,可能可行也可能不可行。你没有必要遵循这种形式转化,你可以自己创造和实现不同的方法。
解题思路
思路可以概括为一句话:假如x是多叉树任意一个节点,那么则让x的所有孩子,都在二叉树中x的左孩子的右边界上。
举例如下:
比如一颗N叉树如下:
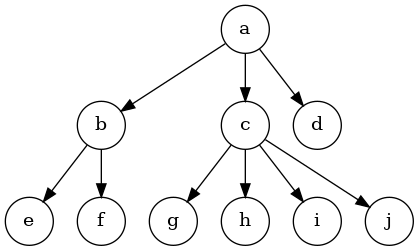
上述思路转换后的二叉树如下:
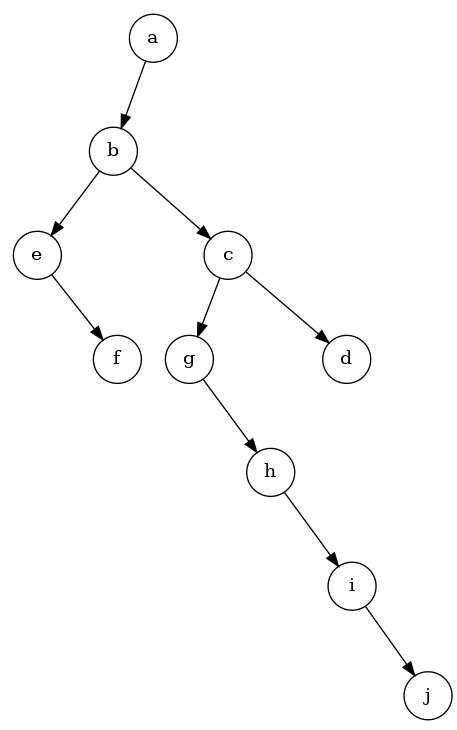
我们可以看到,a的孩子,全部挂在了a左子树的右边界 b->c->d
b的孩子,也挂在了b左孩子的右边界 e->f
c的孩子,全部挂在了c的左孩子的右边界 g->h->i->j
代码详解
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
|
/**
* Definition for a Node.
* type Node struct {
* Val int
* Children []*Node
* }
*/
/**
* Definition for a binary tree node.
* type TreeNode struct {
* Val int
* Left *TreeNode
* Right *TreeNode
* }
*/
type Codec struct {
}
func Constructor() *Codec {
return &Codec{}
}
func (this *Codec) encode(root *Node) *TreeNode {
if root == nil {
return nil
}
btRoot := &TreeNode{Val: root.Val}
btRoot.Left = this.ec(root.Children)
return btRoot
}
// 将所有孩子挂在btRoot的左孩子右边界上
func (this *Codec) ec(children []*Node) *TreeNode {
var head *TreeNode
var cur *TreeNode
for _, child := range children {
childBT := &TreeNode{Val: child.Val}
if head == nil {
head = childBT
} else {
cur.Right = childBT
}
cur = childBT
cur.Left = this.ec(child.Children)
}
return head
}
func (this *Codec) decode(root *TreeNode) *Node {
if root == nil {
return nil
}
nRoot := &Node{Val: root.Val, Children: this.dc(root.Left)}
return nRoot
}
func (this *Codec) dc(left *TreeNode) []*Node {
var children []*Node
cur := left
for cur != nil {
n := &Node{Val: cur.Val, Children: this.dc(cur.Left)}
children = append(children, n)
cur = cur.Right
}
return children
}
|
代码详见:
code05_encode_nary_tree_to_binary_tree.go
算法面试题:给定一颗二叉树,返回最大的宽度
比如:
1
2
3
4
5
6
7
8
9
10
11
|
1
/ \
2 3
/ \
4 5
/
6
\
7
第2 3层的宽度都是2,则返回2。
显然不是层数越高宽度越高。
|
思路
我们已经实现了按层遍历,如果我们能在遍历时,记住当前层开始和结束的位置,则能统计每一层的宽度。(这里假设您已经对按层遍历的流程比较熟悉,如不熟悉的,请参考前面的按层遍历代码。)我们只需要通过有限几个变量,就能做到,这几个变量的定义如下:
- max : 统计全局最大的宽度,当计算到某一层宽度比max大时,更新max,最终返回max。
- curEnd(*TreeNode类型):记录遍历的当前层的结束节点。
- nextEnd(*TreeNode类型):记录即将遍历的下一层的结束节点,为下一层遍历做准备。
- count: 当前层宽度统计,每当发现当前层从队列中弹出一个节点,则count++。
具体流程举例如下:
我们假设一颗树的结构如下:
1
2
3
4
5
6
7
|
1
/ \
2 3
/ \ \
4 5 6
/ \
7 8
|
流程执行的过程如下:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
|
max=0; curEnd=nil; nextEnd=nil; count=0;
1. 遍历到1,1入队列,curEnd = 1; queue = [1];
2. 1出队列,count++;
1左孩子2入队列,nextEnd=2;
1右孩子3入队列,nextEnd=3;
由于1==curEnd,当前行结束,max更新为1,同时curEnd=nextEnd,nextEnd=nil, count清零;
最终:queue=[3,2]; count=0; max=1; curEnd=3; nextEnd=nil
3. 2出队列,count++,count=1;
2左孩子4入队列,nextEnd=4;
2右孩子5入队列,nextEnd=5;
最终:queue=[5,4,3]; count=1; max=1; curEnd=3; nextEnd=5;
4. 3出队列,count++,count=2;
3没有左孩子,不如队列
3右孩子入队列,nextEnd=6;
由于3==curEnd,当前行结束,max更新为2,同时curEnd=nextEnd,nextEnd=nil, count清零
最终:queue=[6,5,4];count=0; max=2; curEnd=6; nextEnd=nil;
5. 4出队列,count++,count=1,4没有孩子,不入队列。
6. 5出队列,count++,count=2;
5的左孩子7入队列,nextEnd=7;
最终:queue=[7,6]; count=2; max=2; curEnd=6; nextEnd=7;
7. 6出队列,count++,count=3;
6的右孩子8入队列,nextEnd=8;
由于6==curEnd,当前行结束,max更新为3,同时curEnd=nextEnd,nextEnd=nil, count清零
最终:queue=[8,7]; count=0; max=3; curEnd=8; nextEnd=nil;
8. 7出队列,count++,count=1;
7没有孩子,不入队列,7也不等于curEnd,当前行继续;
9. 8出队列,count++,count=2;
8没有孩子,不入队列;
由于8==curEnd,当前行结束,max=3比2大不更新,同时curEnd=nextEnd,nextEnd=nil, count清零。
最终:queue=[]; count=2; max=3; curEnd=nil; nextEnd=nil;
此时队列为空,整个遍历流程结束,返回最大值3。
|
总结:每次遍历到一个节点(指这个节点出队列)时,提前准备下一层的最后一个节点,并不断往右推,当前层结束时,nextEnd一定正好推到了下一层的最后一个节点。
同时通过curNext能知道是否当前层结束了。
代码实现
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
|
package class_11_12
import "ZuoShenAlgorithmGo/utils"
// 给定一颗二叉树,返回最大的宽度
// MaxWidth 不使用容器实现
func MaxWidth(root *TreeNode) int {
if root == nil {
return 0
}
// 生成一个TreeNode类型的队列
queue := NewTreeNodeQueue()
var curEnd = root // 当前行的结束
var nextEnd *TreeNode // 下一行的结束
var count int // 统计当前行的宽度
var max int // 整个树最大的宽度
// 先将头节点入队
queue.Push(root)
// 队列不为空,则一直进行
for !queue.IsEmpty() {
// 弹出一个节点,就统计当前行宽度+1
cur := queue.Poll()
count++
// 只要有左右子树,则一定是下一行的,下一行结束节点先记住
if cur.Left != nil {
queue.Push(cur.Left)
nextEnd = cur.Left
}
if cur.Right != nil {
queue.Push(cur.Right)
nextEnd = cur.Right
}
// 判断当前行是否现在结束了,如果当前行结束了,则统计max,并重置count,curEnd,nextEnd 3个变量
if cur == curEnd {
max = utils.Max(max, count)
count = 0
curEnd = nextEnd
nextEnd = nil
}
}
return max
}
// MaxWidthWithMap 使用容器实现
func MaxWidthWithMap(root *TreeNode) int {
if root == nil {
return 0
}
// 生成一个TreeNode类型的队列
queue := NewTreeNodeQueue()
// 生成一个map记录每个节点在第几层
nodeLevelMap := make(map[*TreeNode]int)
curLevel := 1 // 记录当前在第几层
count := 0 // 统计当前层的个数
max := 0 // 统计整棵树最大的宽度
// 先将头节点入队,同时标记root在第1层
queue.Push(root)
nodeLevelMap[root] = 1
// 队列不为空,则一直进行
for !queue.IsEmpty() {
// 弹出一个节点
cur := queue.Poll()
// 获取这个节点在第几层
curNodeLevel := nodeLevelMap[cur]
// 如果还是当前层,则当前层的数量++
if curNodeLevel == curLevel {
count++
} else {
// 如果不是当前层了,则curLevel跳到下一层
curLevel = curNodeLevel
count = 1
}
max = utils.Max(max, count)
// 只要有左右子树,则一定是下一行的,入队同时将层数记录下来
if cur.Left != nil {
queue.Push(cur.Left)
nodeLevelMap[cur.Left] = curLevel + 1
}
if cur.Right != nil {
queue.Push(cur.Right)
nodeLevelMap[cur.Right] = curLevel + 1
}
}
return max
}
|
代码详见:
code05_tree_max_width.go
面试题:给定一个有父指针的二叉树的某个节点,返回该节点的后继节点
二叉树的节点结构如下:
1
2
3
4
5
6
|
type TreeNodeP struct {
Val int
Parent *TreeNodeP
Left *TreeNodeP
Right *TreeNodeP
}
|
给定这颗二叉树的一个节点,返回这个二叉树的后继节点,如果没有,则返回nil。
后继节点
后继节点是一颗二叉树按照中序遍历顺序排列后,节点的后面一个节点。比如一颗二叉树如下:
1
2
3
4
5
6
7
8
9
|
a
/ \
b c
/ \ / \
d e f g
/ \
h i
\
j
|
按照中序遍历,则为dbeahfijcg,那么b的后继节点为e,c的后继节点为g。
思路
正常来讲,如果要找二叉树的某个节点的后继节点,需要给定头节点和要找的节点X,先根据头节点生成中序遍历的顺序,然后再找X在中序遍历中的下一个。
这个过程的时间复杂度是O(N)(N是节点个数)。
现在X节点能找到父节点,此时可以只给你X节点,不给你头节点,也能实现。因为X可以一直往上找,直到找到根节点,就又可以生成中序遍历。
但是这种方式仍然是O(N)的复杂度,有没有一种方式,能实现O(K)的复杂度呢?(K是当前节点与下一个节点的距离。)比如上面例子中的e节点的后继是根节点a,e 与 a的距离只有2。而遍历整颗树的规模是10。
答案是有的,流程如下:
- 如果X有右孩子,则X的后继是X右孩子的最左节点。比如上面的a,后继是右子树的最左节点h。
- 如果X没有右孩子,则X一直沿着父指针往上找,如果是父亲的右子树,则继续,直到是它父亲的左孩子,则这个父亲是当前X的后继。
比如上面的j节点,找到父亲i,j是i的右孩子,继续;找到i的父亲f,i是f的右孩子,继续;找到f的父亲c,f是c的左孩子,停,则c是i的后继。
- 如果2过程一直找到空了,都没找到哪个节点是它父亲的左孩子,则说明这个节点是整棵树的最右节点,没有后继。
这个流程的时间复杂度是O(K)
代码实现
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
|
package class_11_12
import "ZuoShenAlgorithmGo/class_03"
// 给定一个有父指针的二叉树的某个节点,返回该节点的后继节点
type TreeNodeP struct {
Val int
Parent *TreeNodeP
Left *TreeNodeP
Right *TreeNodeP
}
func GetSuccessorNode(node *TreeNodeP) *TreeNodeP {
if node == nil {
return nil
}
// 有右子树,则获取右子树最左侧的节点
if node.Right != nil {
return getLeftMost(node.Right)
} else {
// 没有右子树
parent := node.Parent
for parent != nil && parent.Right == node {
node = parent
parent = node.Parent
}
return parent
}
}
// 找一棵树最左侧的节点
func getLeftMost(node *TreeNodeP) *TreeNodeP {
// 一直往左划,直到划到Left为空
cur := node
for cur.Left != nil {
cur = cur.Left
}
return cur
}
// GetSuccessorNodeNormal 普通方法找到后继节点,同时做对数器测试
func GetSuccessorNodeNormal(node *TreeNodeP) *TreeNodeP {
if node == nil {
return nil
}
// 找到根节点
root := node
for root.Parent != nil {
root = root.Parent
}
// 中序遍历
inQueue := class_03.NewMyQueue[*TreeNodeP]()
inTreeNodeP(root, inQueue)
// 中序遍历顺序弹出,并找下一个
for !inQueue.IsEmpty() && inQueue.Peek() != node {
inQueue.Poll()
}
// 弹出当前节点
inQueue.Poll()
// 弹出当前节点的下一个
return inQueue.Poll()
}
func inTreeNodeP(root *TreeNodeP, inQueue *class_03.MyQueue[*TreeNodeP]) {
if root == nil {
return
}
inTreeNodeP(root.Left, inQueue)
inQueue.Push(root)
inTreeNodeP(root.Right, inQueue)
}
|
代码详见:
code06_successor_node.go
微软面试题:二叉树折纸问题
请把一段纸条竖着放在桌子上,然后从纸条的下边向上方对折1次,压出折痕后展开。此时折痕是凹下去的,即折痕突起的方向指向纸条的背面。 如果从纸条的下边向上方连续对折2次,压出折痕后展开,此时有三条折痕,从上到下依次是下折痕、下折痕和上折痕。
给定一个输入参数N,代表纸条都从下边向上方连续对折N次。 请从上到下打印所有折痕的方向。
例如:N=1时,打印: down N=2 时,打印: down down up
思路
我们折1次时,出现1个凹折痕,记作1凹
我们折2次时,在1折痕的上下分别出现凹折痕和凸折痕,我们记作2凹和2凸,此时是 凹 凹 凸
我们折3次时,在每个2折痕上下分别出现凹折痕和凸折痕,我们记作3凹和3凸,此时是 凹 凹 凸 凹 凹 凸 凸
也就是说,我们每折1次,都是在上次新出现的每个折痕上下分别出现一个凹和凸折痕。这是一个完全二叉树。表示如下:
1
2
3
4
5
6
7
8
|
我们用|表示凹折痕,用}表示凸折痕,对折3次的样子如下:
1凹
/ \
2凹 2凸
/ \ / \
3凹 3凸 3凹 3凸
上 【 | | } | | } } 】 下
|
而题目的目的,就是打印上面这颗树的中序遍历。
这颗二叉树有以下几个特点:
- 头节点是凹。
- 每个左子树的头节点是凹。
- 每个右子树的头节点是凸。
代码实现
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
|
package class_11_12
import "fmt"
// 二叉树折纸问题
// PrintAllFolds 折N次依次打印折痕顺序
func PrintAllFolds(n int) {
// 从第1层开始打印(从根节点开始),而且总共有n,且第1层的折痕是凹折痕
process(1, n, true)
fmt.Println()
}
// 递归过程:想象一个如题的二叉树,当前是在这个二叉树的第i层的某个节点,总共有N层。
// 并且当前节点的折痕是 down == true 则是凹折痕,false 则为凸折痕
// 打印这个子树的中序遍历
func process(i int, n int, down bool) {
// 如果当前层已经超过了总层数,则返回
if i > n {
return
}
// 先左再头再右,中序遍历。
// 先打印左子树,我的左子树一定是凹折痕,且层数比我大1
process(i+1, n, true)
// 再打印我自己
if down {
fmt.Print("凹 ")
} else {
fmt.Print("凸 ")
}
// 最后打印右子树,我的右子树一定是凸折痕,且层数比我大1
process(i+1, n, false)
}
|
代码详见:
code07_paper_folding.go